Normalization Strategies: Batch vs Layer vs Instance vs Group Norm

Normalization has been a standard technique for vision-related tasks for a while, and there are dozens of different strategies out there. It can be overwhelming to try to understand each of them.
Recall that no matter what strategy we pick, the goal of normalization is to “shift” the target samples into a certain distribution. This is usually good for stabilizing training, as normalization standardizes the input.
Let’s look at how the top 4 most used normalization strategies work, and why you might choose one over another. Throughout this post will be looking at an example with an input dimension of N x C x H x W, where N is the batch size, C is channels, and H x W is the size of an image.
The diagram below illustrates the mechanics behind batch, layer, instance, and group normalization. The shades indicate the scope of each normalization, and the solid lines represent the axis on which the normalizations are applied.
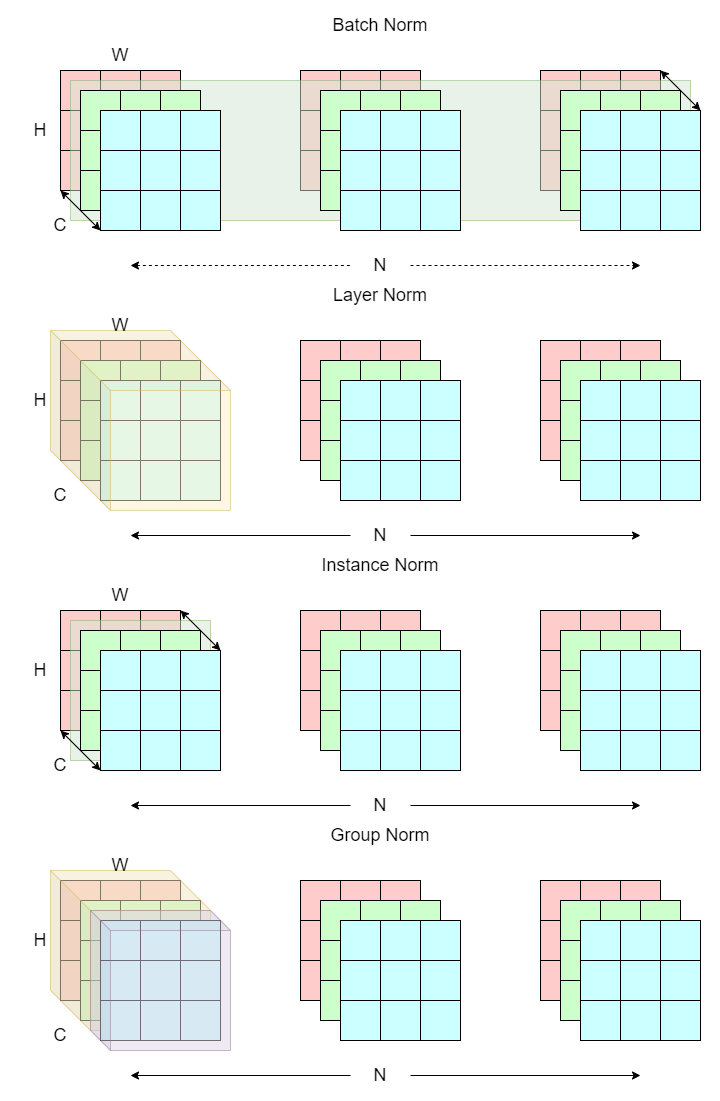
common normalization strategies
Batch Normalization
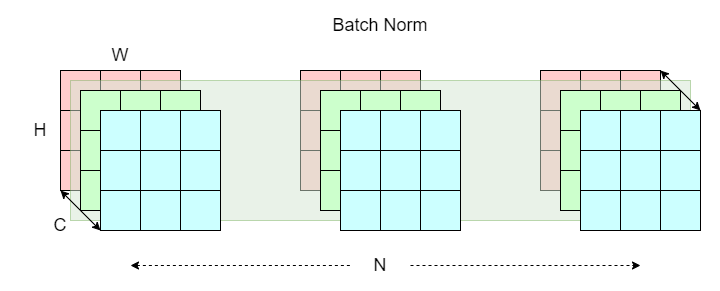
batch normalization
Batch normalization (BN) is the first normalization strategy ever introduced to the world of deep neural networks. Benefits of using batch norm include faster training speed and greater input stability, which significantly reduces the chance of gradient explosion/vanishing.
This technique involves normalizing on the “batch layer” (represented as the green shade) N x H x W across the channel dimension C.
Quoting from this article, think of the structure of an image as a book. Each book (C x H x W) has multiple pages (C), with each page having height and width H x W. Now think of a row of N books on a bookshelf as a batch of images (N x C x H x W). To apply batch norm, we pick the first page of each book and apply normalization. We then repeat this process for the rest of C - 1 pages.
A problem with batch norm is that it yields poor results when there are not enough samples (N). It can also be time-consuming due to the way it is implemented. This is not ideal in certain scenarios such as tasks with low batch size, or tasks with variable batch size (online learning).
Layer Normalization
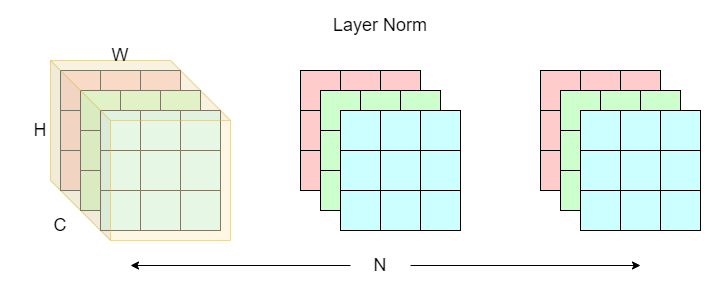
layer normalization
Layer normalization (LN) fixes the sample size issue that batch norm suffers from. This technique involves normalizing on the “layers” (yellow shade) C x H x W, which is basically a single image sample, across the batch dimension N. Note that layer norm is not batch dependent.
Continuing our analogy to books, think of the structure of an image as a book. Each book (C x H x W) has multiple pages (C), with each page having height and width H x W. Now think of a row of N books on a bookshelf as a batch of images (N x C x H x W). To apply layer norm, we pick the first book (C x H x W) and apply normalization. We then repeat this process for the rest of N - 1 books.
Layer norm is widely used in sequential modeling (RNN) and the transformer architecture, as NLP tasks often have variable batch sizes (sentence length), it is more intuitive to just normalize on a single word with layer norm.
Instance Normalization
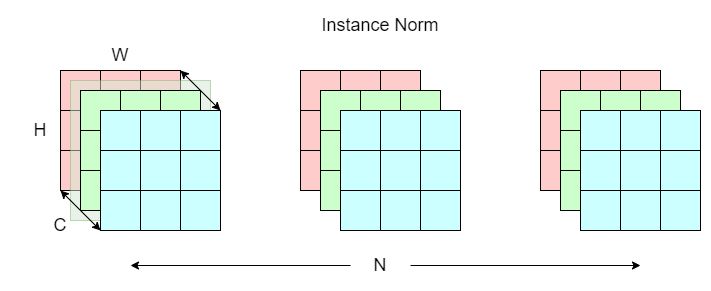
instance normalization
Instance norm (IN), also known as contrast normalization, is first used in the StyleNet paper for transferring image style. This technique involves normalizing on a single “layer” (green shade) H x W across both the channel (C) and batch (N) dimensions.
Again, think of the structure of an image as a book. Each book (C x H x W) has multiple pages (C), with each page having height and width H x W. Now think of a row of N books on a bookshelf as a batch of images (N x C x H x W). To apply instance norm, we normalize on the first page of the first book (H x W). We then repeat this process for the rest of the C - 1 pages for N - 1 books.
Group Normalization
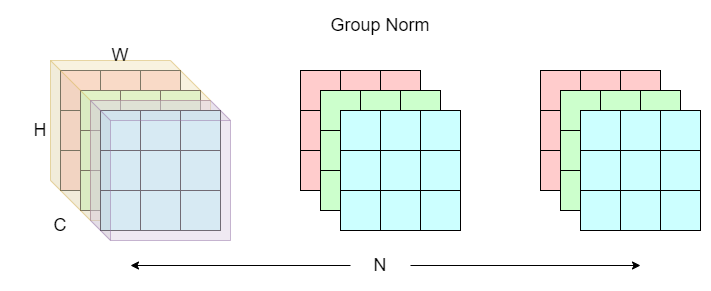
group normalization
Group normalization (GN) is a mixture of instance and layer norm. The idea is to split the channel dimensions into “groups” (yellow and purple shades). Normalization is then computed on each group across the batch N dimension just like instance norm.
Same thing, think of the structure of an image as a book. Each book (C x H x W) has multiple pages (C), with each page having height and width H x W. Now think of a row of N books on a bookshelf as a batch of images (N x C x H x W). To apply group norm, we first divide the pages into C / G groups. We then normalize within every group in the first book. Finally, repeat this process for the rest of N - 1 books.
Conclusion
Here we summarize the normalization strategies mentioned above.
- Batch norm treat each
N x H x Was a unit of normalization. - Layer norm treat each
C x H x Was a unit of normalization. - Instance norm treat each
H x Was a unit of normalization. - Group norm first divides the channel dimension into
C / Ggroups, then treats each(C / G) x H x Was a unit of normalization.
Finally, check out papers with code for popular normalization strategies not included in this post, and their detailed theory.